Vision Language Pre-training Model
Multimodal model has significantly evolved in the past few years. The input of model is no longer constraint on one single modality like test, image, audio or video. but take cross-modal input (like image-text pairs) into consideration for representation learning, which could be applied to the scenarios like visual question answering, image-text retrieval, image captioning and so on. This post will give an overall introduction about the classic vision-language pre-training model from OSCAR, VinVL, CLIP, ALIGN, SimVLM and ALBEF.
Humans perceive the world through many channels, such as images viewed by the eyes or voices heard by the ears. Though any individual channel might be incomplete or noisy, humans can naturally align and fuse the information collected from multiple channels to grasp the key concepts needed for a better understanding of the world. One of the core aspirations in artificial intelligence is to develop algorithms that endow computers with an ability to effectively learn from multi-modality (or multi-channel) data, similar to sights and sounds attained from vision and language that help humans make sense of the world around us. For example, computers could mimic this ability by searching the most similar images for a text query (or vice versa) and describing the content of an image using natural language.
1.OSCAR
OSCAR (Object-Semantics Aligned Pre-training) uses object tags detected in images as anchor points to significantly ease the learning of alignments.
OSCAR pipeline

Illustration of process about representing image-text pair into semantic space
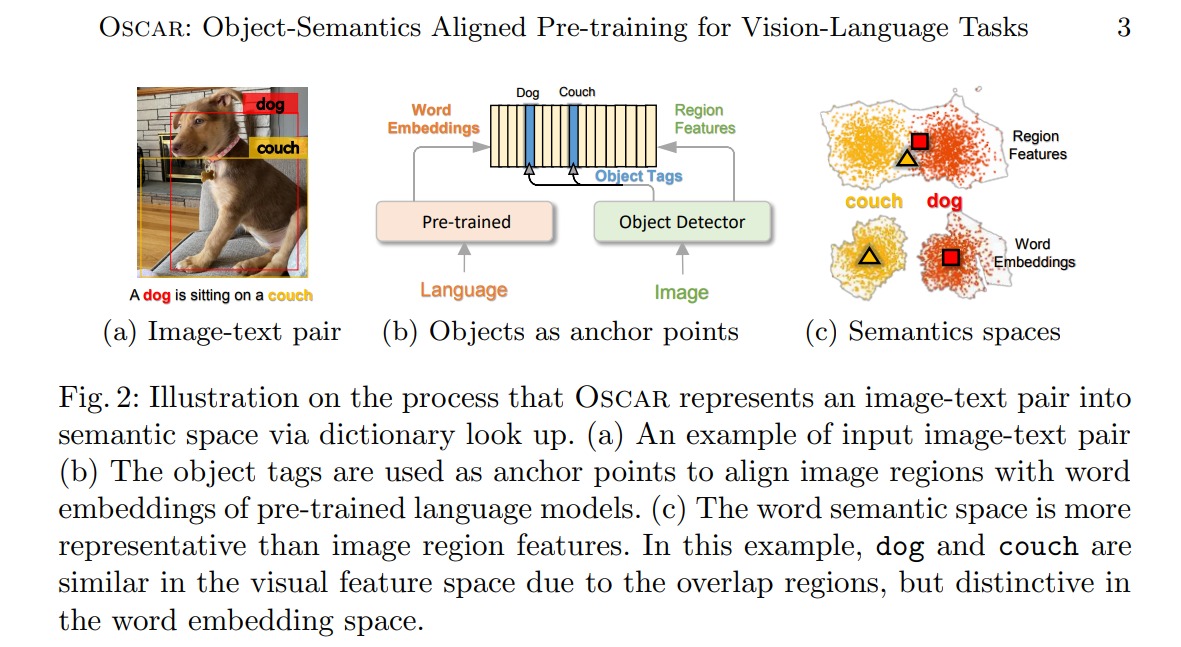
Illustration of pretraining

Pretraining objective: Depending on how the three items in the triplet are grouped, we view the input from two different perspectives: a modality view and a dictionary view. Each allows us to design a novel pre-training objective: 1) a masked token loss for the dictionary view, which measures the model’s capability of recovering the masked element (word or object tag) based on its context; 2) a contrastive loss for the modality view, which measures the model’s capability of distinguishing an original triple and its “polluted” version (that is, where an original object tag is replaced with a randomly sampled one).
2.VinVL
VinVL (Visual features in Vision-Language) develops an improved object detection model to provide object-centric representations of images, which feeds the visual features generated by the new object detection model into a Transformer-based VL fusion model OSCAR. This model can generate representations of a richer collection of visual objects and concepts, and it turns out that visual features matter significantly in VL models.
A typical VL system uses a modular architecture with two modules to achieve VL understanding:
-
An image encoding module, also known as a visual feature extractor, is implemented using convolutional neural network (CNN) models to generate feature maps of input image. The CNN-based object detection model trained on the Visual Genome (VG) dataset is the most popular choice before our work.
-
A vision-language fusion module maps the encoded image and text into vectors in the same semantic space so that their semantic similarity can be computed using cosine distance of their vectors. The module is typically implemented using a Transformer-based model, such as OSCAR.

3.CLIP
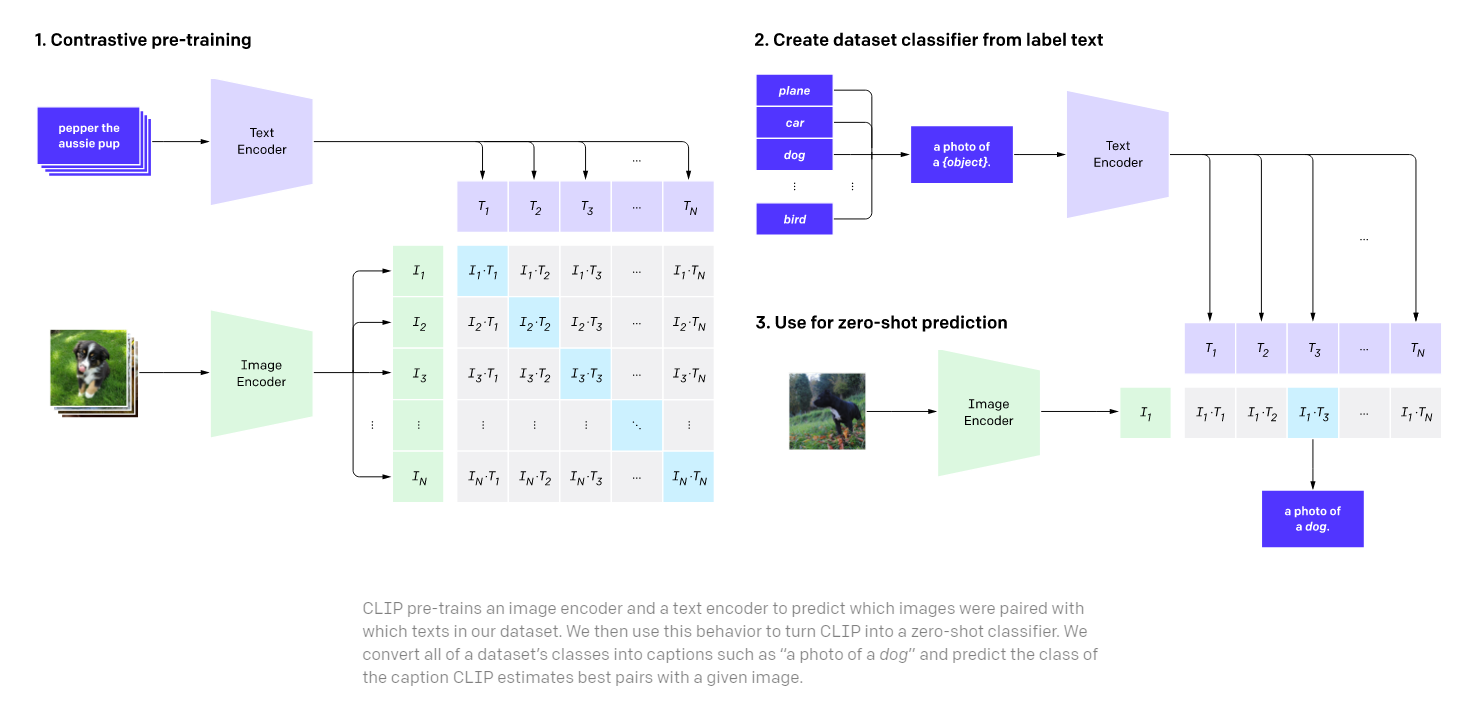
CLIP (Contrastive Language–Image Pre-training) efficiently learns visual concepts from natural language supervision. CLIP can be applied to any visual classification benchmark by simply providing the names of the visual categories to be recognized, similar to the “zero-shot” capabilities of GPT-2 and GPT-3.
It shows that scaling a simple pre-training task is sufficient to achieve competitive zero-shot performance on a great variety of image classification datasets. Our method uses an abundantly available source of supervision: the text paired with images found across the internet. This data is used to create the following proxy training task for CLIP: given an image, predict which out of a set of 32,768 randomly sampled text snippets, was actually paired with it in our dataset.
CLIP model architecture is as below.
4.ALIGN
ALIGN (A Large-scale ImaGe and Noisy-Text Embedding) leverages a noisy dataset of over one billion image and alt-text pairs, obtained without expensive filtering or post-processing steps in the Conceptual Captions dataset.
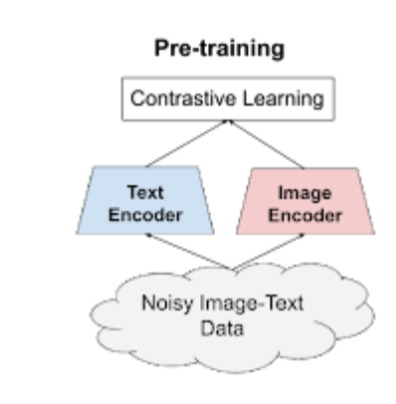
For the purpose of building larger and more powerful models easily, we employ a simple dual-encoder architecture that learns to align visual and language representations of the image and text pairs. Image and text encoders are learned via a contrastive loss (formulated as normalized softmax) that pushes the embeddings of matched image-text pairs together while pushing those of non-matched image-text pairs (within the same batch) apart. The large-scale dataset makes it possible for us to scale up the model size to be as large as EfficientNet-L2 (image encoder) and BERT-large (text encoder) trained from scratch. The learned representation can be used for downstream visual and vision-language tasks.
Dual encoder architecture of ALIGN is illustrated below:
The resulting representation can be used for vision-only or vision-language task transfer. Without any fine-tuning, ALIGN powers cross-modal search – image-to-text search, text-to-image search, and even search with joint image+text queries, examples below.

Multimodal (Image+Text) Query for Image Search: A surprising property of word vectors is that word analogies can often be solved with vector arithmetic. A common example, “king – man + woman = queen”. Such linear relationships between image and text embeddings also emerge in ALIGN. Specifically, given a query image and a text string, we add their ALIGN embeddings together and use it to retrieve relevant images using cosine similarity.

5.SimVLM
SimVL (Simple Visual Language Model Pre-training with weak supervision) is trained end-to-end with a single unified objective named prefix language model objective which receives the leading part of a sequence (the prefix) as inputs, then predicts its continuation. Also is albe to directly take in raw images as inputs.
The model architecture of SimVL is as below.

The model is pre-trained on large-scale web datasets for both image-text and text-only inputs. For joint vision and language data, we use the training set of ALIGN which contains about 1.8B noisy image-text pairs. For text-only data, we use the Colossal Clean Crawled Corpus (c4) dataset introduced by T5, totaling 800G web-crawled documents.
Zero-shot application

6.ALBEF
ALBEF (Align Before Fuse) is a new vision-language representation learning framework which achieves state-of-the-art performance by first aligning the unimodal representations before fusing them.
The limitation of previous VL models:
- for the model like CLIP and ALIGN, they lack the ability to model complex interactions between image and text, hence they are not good at tasks that require fine-grained image-text understanding.
- The widely used pre-training objectives such as masked language modeling (MLM) are prone to overfitting to the noisy text which would hurt representation learning.
- most methods use a pre-trained object detector for image feature extraction, which is both annotation-expensive and computation-expensive.
ALBEF model
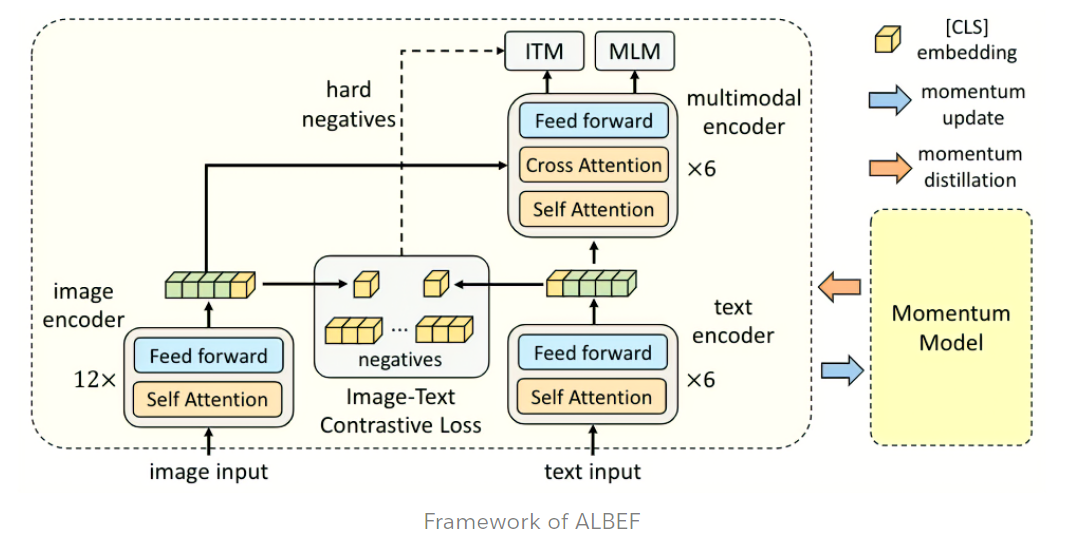
As illustrated in the figure above, ALBEF contains an image encoder (ViT-B/16), a text encoder (first 6 layers of BERT), and a multimodal encoder (last 6 layers of BERT with additional cross-attention layers).