pre-training model in NLP
The technique of word embedding method and pre-training model is to get the vector representation of word or sentence by exploiting the contextual information of word or sentence as accurately as possible. These numerical value of vector representation can be subsequently used for the downstream NLP task.
1.Word2Vec
Word2Vec is a method to learn the vector representation of word embedding from large datasets.
It uses the Continuous Skip-gram Model to predict words within a certain range before and after the current word in the same sentence. Continuous Bag-of-Words Model (CBOW) is another mothod to train the model by predicting the middle word based on surrounding context words. The context consists of a few words before and after the current (middle) word.
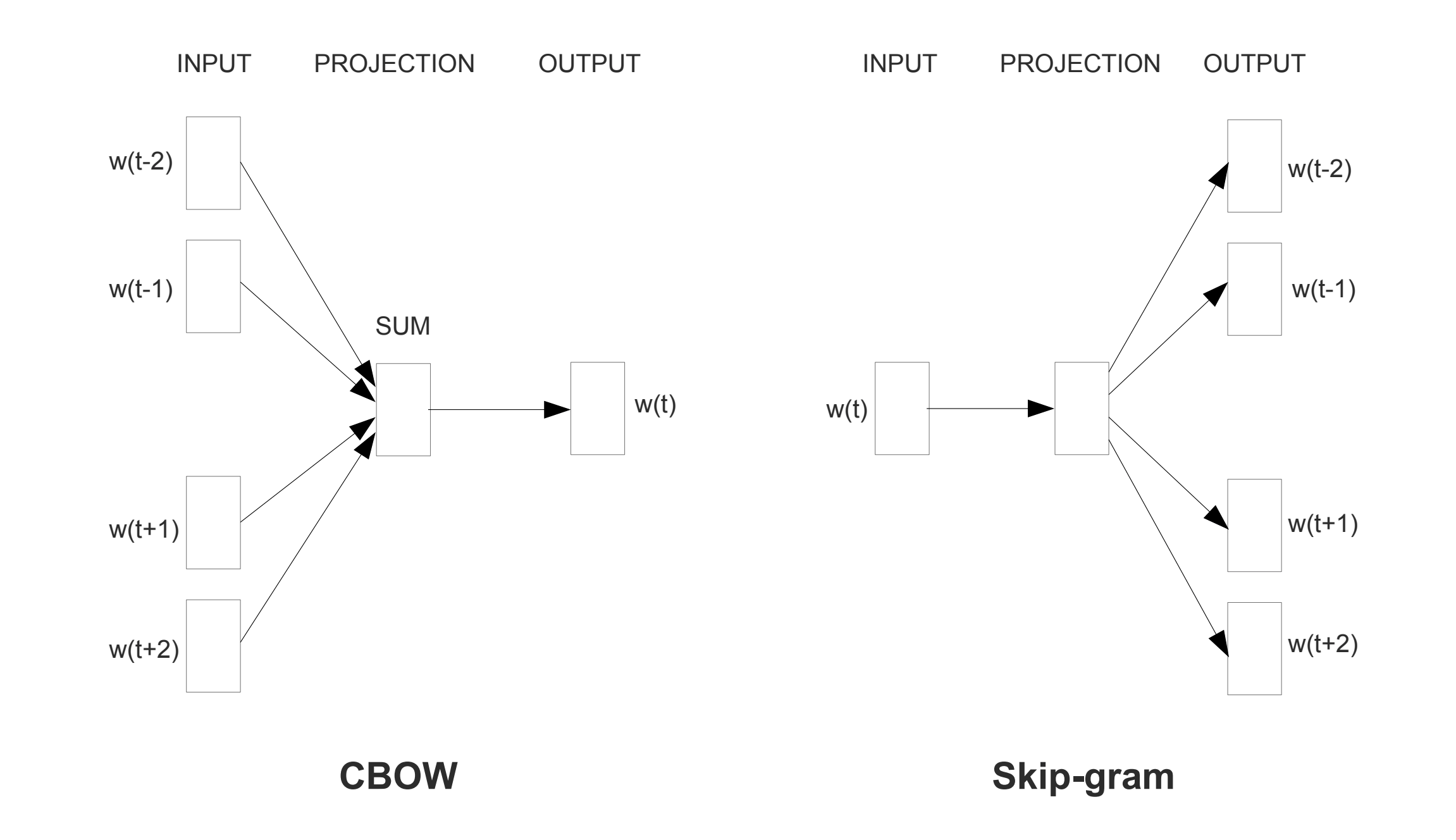
Here is the explanation of how to form the training examples using word2vec.

The training objective of the Skip-gram model is to find word representations that are useful for predicting the surrounding words in a sentence or a document. More formally, given a sequence of training words \( w_1,w_2,\cdot,w_T\), the objective of the Skip-gram model is to maximize the average log probability
\[\begin{equation} \frac{1}{T} \sum_{t=1}^{T} \sum_{-c \leq j \leq c, j \neq 0} \log p(w_{t+j}|w_t) \end{equation}\]where \(c\) is the size of the training context.
\[\begin{equation} p(w_{t+j}|w_t) = p(w_{O}|w_I) = \frac{e^{v_{w_O}^{\prime} v_{w_I}}}{\sum_{w=1}^{W} e^{ v_w^{\prime} v_{w_I} }} \end{equation}\]where \( v_w\) and \( v_w^{\prime}\) are the input and output vector representation of \( w \), and \( W\) is the number of words in the vocabulary. the noticeable problem for this is huge computation cost proportional to the number of the word vocabulary for the Softmax function . To cope with this disadvantage, Noise Contrastive Estimation (NCE) is proposed, which uses Negative Sampling to sample some negative samples for the input word according to one noise distribution instead of using all the words in the vocabulary to reduce the computation cost.
After training, the vector representation of the words with similar semantic meaning will be more close, in contrast, the vector representation of the words with different semantic meaning will be less similar.

But, there are some problems that restricts the performance of Word2Vec.
- One is: there is one fixed vector representation for one word, so it is not suitable for synonym word (polysemy),
- another is: Word2Vec takes less contextual information of current word into consideration, the representation is a little shallow,
2.ELMo
ELMo (Embeddings from Language Models) is a deep contextualized word representation that models both complex characteristics of word use (e.g., syntax and semantics), and how these uses vary across linguistic contexts (i.e., to model polysemy). These word vectors are learned functions of the internal states of a deep bidirectional language model (biLM), which is pre-trained on a large text corpus. They can be easily added to existing models and significantly improve the state of the art across a broad range of challenging NLP problems, including question answering, textual entailment and sentiment analysis.
The architecture of ELMo is:
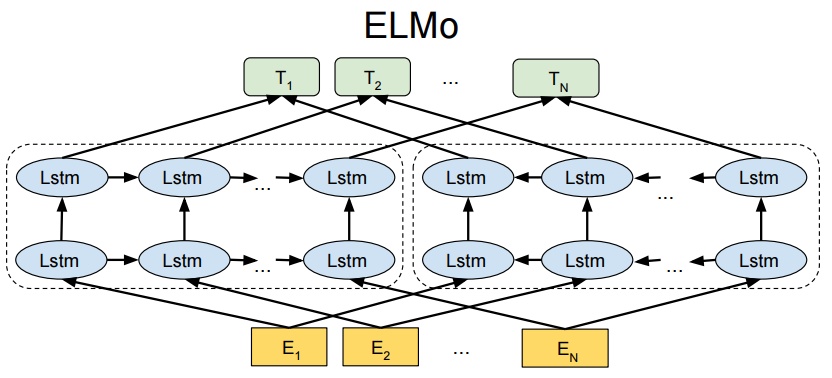
The characteristics of ELMo representations are;
-
Deep: The word representations combine all layers of a deep pre-trained neural network.
-
Contextual: The representation for each word depends on the entire context in which it is used. Instead of using a fixed embedding for each word, ELMo looks at the entire sentence before assigning each word in it an embedding
ELMo comes up with the contextualized embedding through grouping together the hidden states (and initial embedding) in a certain way (concatenation followed by weighted summation).

the dynamic process to get deep contextualized word embedding is as following:

3.Transformer
The Transformer model based on encoder-decoder architecture was proposed in Attention is All You Need.
The sequential nature of Recurrent models (RNN, LSTM) causes that the parallel computation can’t be exploited within the training examples, and the memory constraints limit the batching across training examples as the length of sequence becomes longer.
The Transformer substitutes the traditional attention mechanism using recurrent or convolutional neural networks in encoder and decoder with the simple multi-head self-attention mechanism in the task - machine translation. It allows for significantly more parallelization for the single training example with the help of multi-headed self-attention mechanism, in addition, it can also learn long-range dependency.

The Transformer makes use of multi-headed self-attention to improve the performance of attention layer by concatenation of multi self-attention output result. Multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions. In the decoder, We only need to keep leftward information flow of current input word by masking out all future token values in the input of the softmax which correspond to illegal connections using the masked self-attention.
Since our model contains no recurrence and no convolution, in order for the model to make use of the order of the sequence, we must inject some information about the relative or absolute position of the tokens in the sequence. we add positional encoding to the input embeddings at the bottoms of the encoder and decoder stacks.
4.Transformer-XL
The central problem of language modelling is how to train a Transformer to effectively encode an arbitrarily long context into a fixed size representation. Given infinite memory and computation, a simple solution would be to process the entire context sequence using an unconditional Transformer decoder. However, this is usually infeasible with the limited resource in practice
The vanilla Transformers are currently implemented with a predefined fixed-length segment context, i.e. a long text sequence is truncated into fixed-length segments of a few hundred characters, and each segment is processed separately. and only train the model within each segment, ignoring all contextual information from previous segments. Under this training paradigm, information never flows across segments in either the forward or backward pass. Chunking simply a sequence into fixed-length segments will lead to the context fragmentation problem.
The Vanilla Transformer with fixed-length context at training time:

During evaluation, at each step, the vanilla model also consumes a segment of the same length as in training, but only makes one prediction at the last position. Then, at the next step, the segment is shifted to the right by only one position, and the new segment has to be processed all from scratch。this evaluation procedure is extremely expensive。
The Vanilla Transformer with fixed-length context at evaluation time:
As a result, it is not able to model dependencies that are longer than a fixed length. In addition, The segments usually do not respect the sentence boundaries, resulting in context fragmentation which leads to inefficient optimization
So the Transformer-XL was proposed to address these issues by enabling network to learn beyond a fixed-length context. Transformer-XL consists of two techniques:
- a segment-level recurrence mechanism
- a relative positional encoding scheme
Segment-level Recurrence:
During training, the representations computed for the previous segment are fixed and cached to be reused as an extended context when the model processes the next new segment. This additional connection increases the largest possible dependency length by \( N \) times, where \( N \) is the depth of the network, because contextual information is now able to flow across segment boundaries. The critical difference lies in that the key vector \( k_{\tau+1}^{n} \) of \( n\text{th} \) layer for current segment \( \tau+1 \) and value vector \( v_{\tau+1}^{n} \) of \( n\text{th} \) layer for current segment \( \tau+1 \) are conditioned on the extended context \( \tilde{h_{\tau+1}^{n-1}} \) of \( (n-1)\text{th} \) layer for current segment \( \tau+1 \) and hence \( h_{\tau}^{n-1} \) ( the hidden vector of \( (n-1)\text{th} \) layer for previous cached segment \( \tau \) ).
The Transformer-XL with segment-level recurrence at training time:
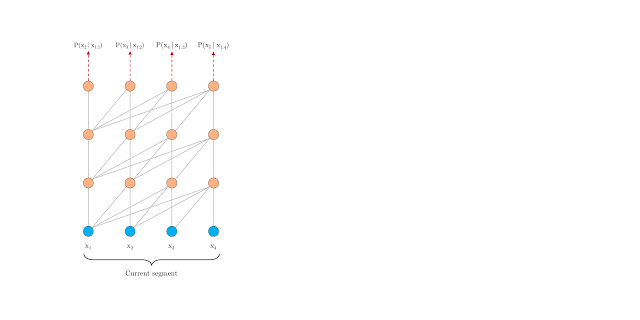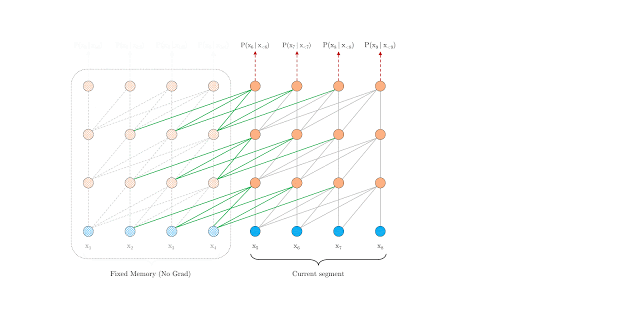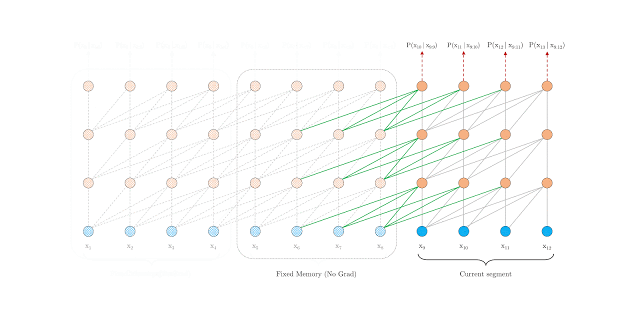
Specifically, during evaluation, the representations from the previous segments can be reused instead of being computed from scratch as in the case of the vanilla model, which leads to a faster evaluation.
The Transformer-XL with segment-level recurrence at evaluation time:
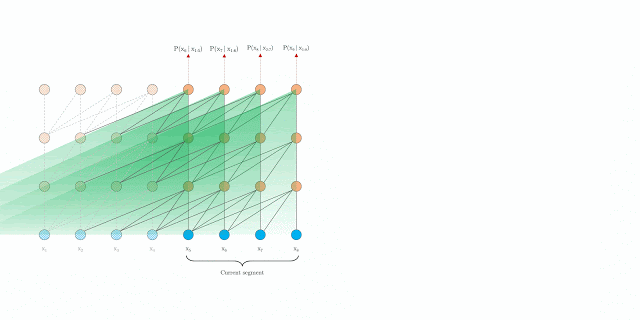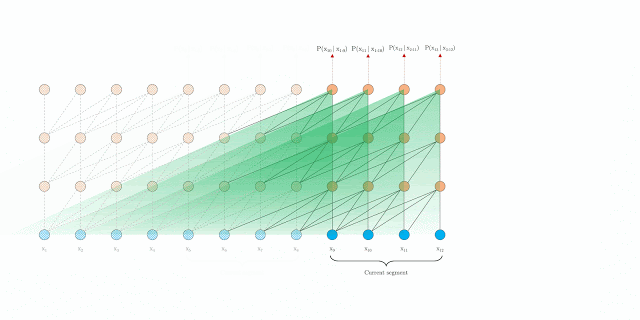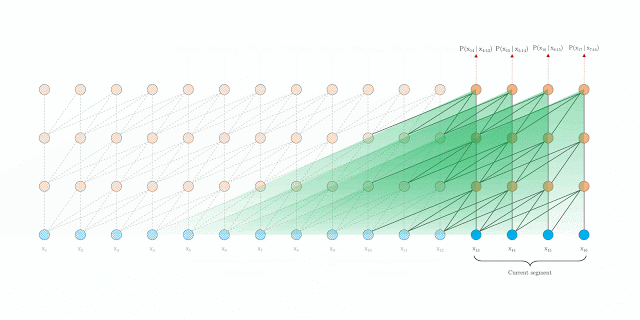
Relative Positional Encodings:
If we use the absolute positional encoding as in the Transformer, it will lose information to distinguish the positional difference between the different segments. To avoid this problem, the relative positional encoding is applied. There is no need for query vector to know the absolute position of each key vector to identify the temporal order of the segment.
The computational procedure for a \( N\text{-layer}\) Transformer-XL with a single attention head. For \( n = 1, \cdots ,N\):

The advantages of Transformer-XL are:
- Transformer-XL learns dependency that is about 80% longer than RNNs and 450% longer than vanilla Transformers.
- Transformer-XL is up to \( 1,800+ \) times faster than a vanilla Transformer during evaluation on language modeling tasks, because no re-computation is needed.
- reduced perplexity.
5.GPT
GPT (Generative Pre-trained Transformer) is a unsupervised pre-training model trained on enormous, diverse and unlabelled corpus of text to further improve the natural language understanding performance in NLP, followed by discriminative fine-tuning on each specific downstream task.
It explores a semi-supervised approach for language understanding tasks using a combination of unsupervised pre-training and supervised fine-tuning. Its goal is to learn a universal representation that transfers with little adaptation to a wide range of tasks such as text classification, question answering, sequence tagging, semantic similarity and so on. This alleviates mostly the dependency on supervised learning with labelled data.
It employs a two-stage training procedure:
- First, for unsupervised pre-training, we use a language modeling objective on the unlabeled data to learn the initial parameters of a neural network model based on Transformer Decoder Block architecture.
- Subsequently, for supervised fine-tuning stage, we adapt these parameters to a target task using the corresponding supervised objective.
The process of pre-training is to predict the word based on its previous words and their contextual representation for one sentence same as the decoder process of Transformer. The way these models actually work is that after each token is produced, that token is added to the sequence of inputs. And that new sequence becomes the input to the model in its next step. This is an idea called auto-regression.
The masked self-attention in decoder is:

The computation of masked self-attention in decoder is:

The process of fine-tuning is as follows:

6.BERT
BERT (Bidirectional Encoder Representation from Transformers) is based on the Transformer Encoder Block unlike GPT. It also uses the framework of unsupervised pra-training with large-scale unlabelled datasets and subsequent supervised fine-tuning on the specific downstream NLP tasks.
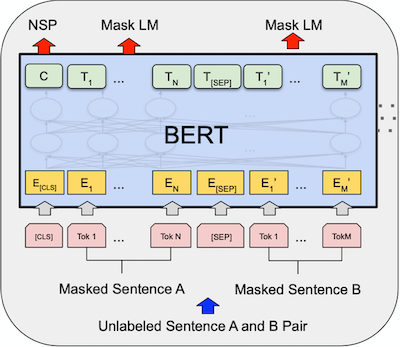
The Pre-training of BERT has two tasks: Next Sentence Prediction (NSP) to predict if two sentences are in right order and Masked Language Model (MLM) to predict the masked words in the input.
The process of MLM is:
- randomly mask approximately 15% words in one sentence
- for these masked words: 80% of them is replaced with the symbol \( MASK \); 10% of them keeps same; and the rest 10% is substituted with one random word.
- The corresponding reason for above step: keep the consistency of input data distribution for training and test period; force model to predict using contextual information; give the model a little ability of error-correction.
The input embedding of BERT is composed of three parts: token embedding, segment embedding and position embedding.
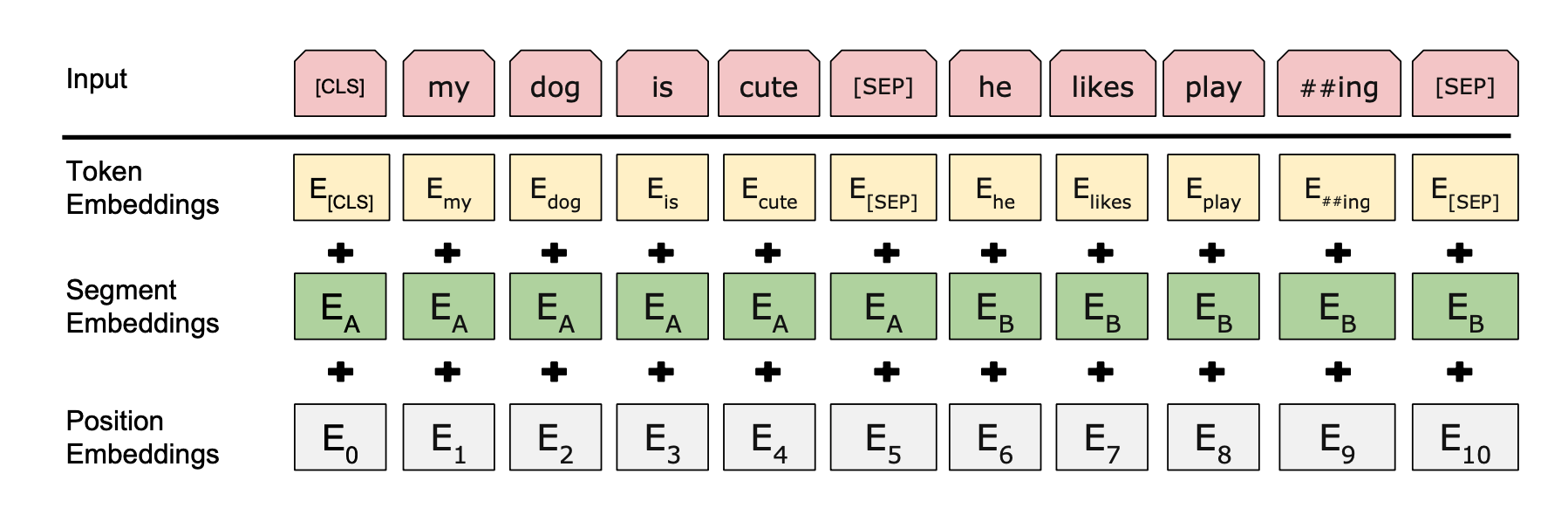
The Pre-training process of BERT:
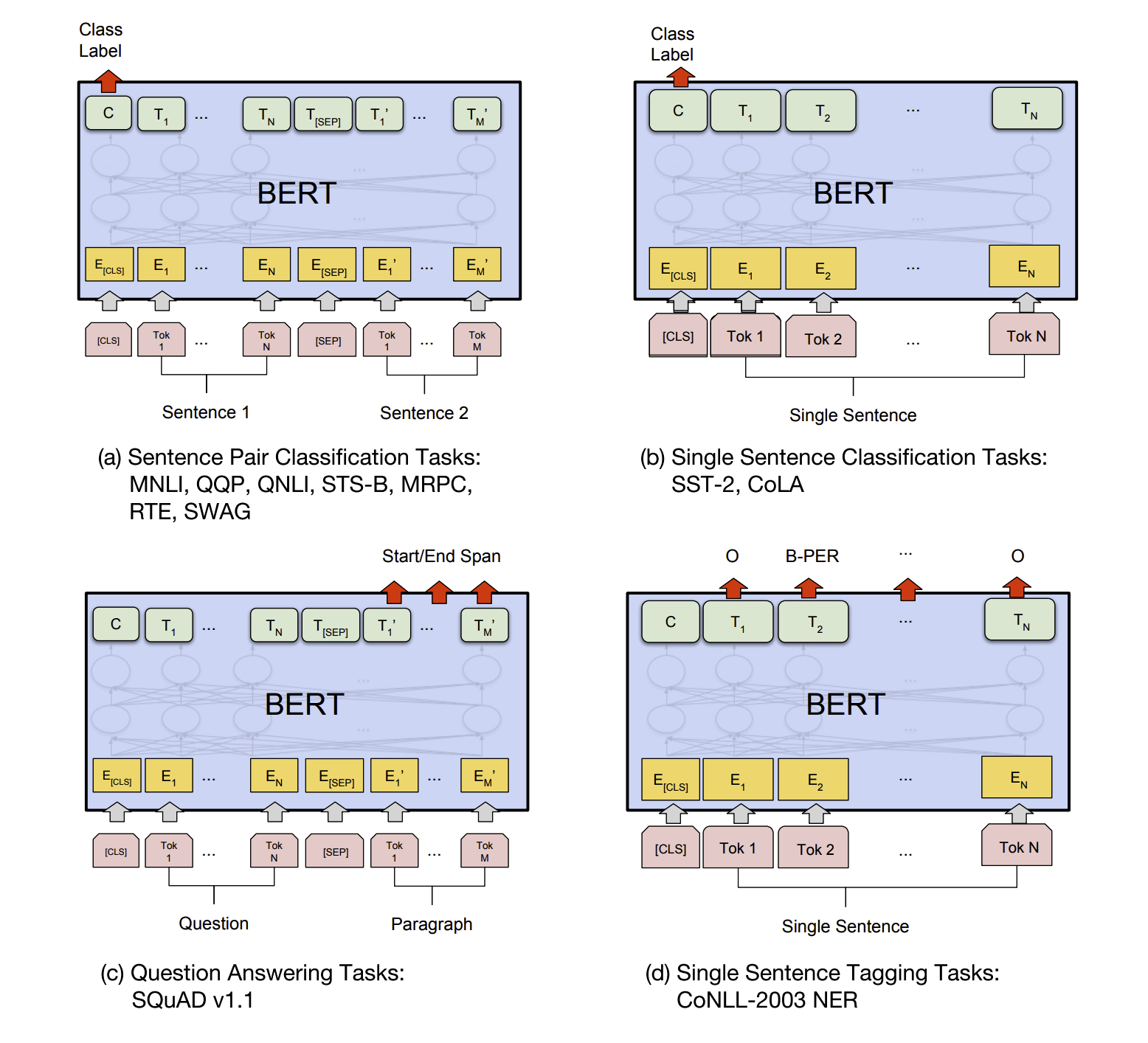
The fine-tuning process of BERT on the downstream NLP tasks:
7.XLNet
An auto-regressive (AR) language model such as GPT is only trained to encode a uni-directional context (either forward or backward), AR language modeling performs pre-training by maximizing the likelihood under the forward auto-regressive factorization. It is not effective at modeling deep bidirectional contexts. however, downstream language understanding tasks often require bidirectional context information. This causes a gap between AR pre-training and subsequent fine-tuning process.
An auto-encoding (AE) language model such as BERT aims to reconstruct the original data from corrupted input. BERT assumes that the predicted tokens are independent of each other given the unmasked tokens. This suffers from a discrepancy between pre-training and fine-tuning because of the mask strategy in training.
Taking the pros and cons of above two methods, XLNet was proposed, it is a permutation-based auto-regressive pre-training method to combine the advantages of AR and AE methods, which enables learning bidirectional contexts by maximizing the expected likelihood over all possible permutations of the factorization order. It overcomes the limitations of BERT and eliminates the independence assumption made in BERT thanks to the auto-regressive formulation. Owing to the permutation operation, the context for each position can consist of tokens from both left and right, which overcomes the limitation of GPT.
The detailed illustration of two-stream self-attention for the target-aware representation:
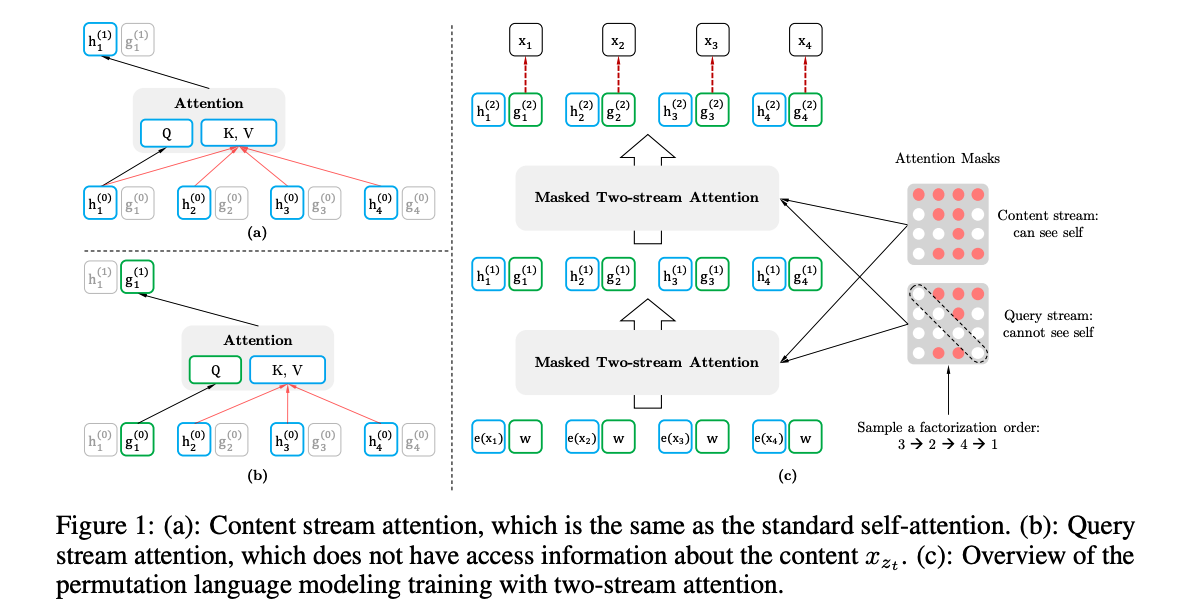
Query stream and content stream have a shared set of parameters as follows:
computation of query stream:
\[\begin{equation} g_{z_t}^{(m)} = Attention(Q = g_{z_t}^{(m - 1)}, \textbf{KV} = \textbf{h}_{z < t}^{(m-1)};\theta) \end{equation}\]computation of content stream:
\[\begin{equation} h_{z_t}^{(m)} = Attention(Q = g_{z_t}^{(m - 1)}, \textbf{KV} = \textbf{h}_{z \leq t}^{(m-1)};\theta) \end{equation}\]During fine-tuning, we can simply drop the query stream and use the content stream as a normal Transformer.
The Illustration of the permutation language modeling objective for predicting \( x_3 \) given the same input sequence \( x \) but with different factorization orders.

The detailed illustration of content stream:

The detailed illustration of query stream:

The main difference is that the query stream cannot do self-attention and does not have access to the token at the position, while the content stream performs normal self-attention.
XLNet also integrate two important techniques in Transformer-XL, namely the relative positional encoding scheme and the segment recurrence mechanism. In addition, XLNet-Large does not use the objective of next sentence prediction. While BERT uses the absolute segment embedding, XLNet uses the relative segment encoding.
8.ERNIE
Enhanced Representation from kNowledge IntEgration (ERNIE) is designed to learn language representation enhanced by knowledge masking strategies, which includes entity-level masking and phrase-level masking. Entity-level strategy masks entities which are usually composed of multiple words. Phrase-level strategy masks the whole phrase which is composed of several words standing together as a conceptual unit. ERNIE achieves the state-of-the-art results on some Chinese NLP tasks.
The different masking strategy between BERT and ERNIE:
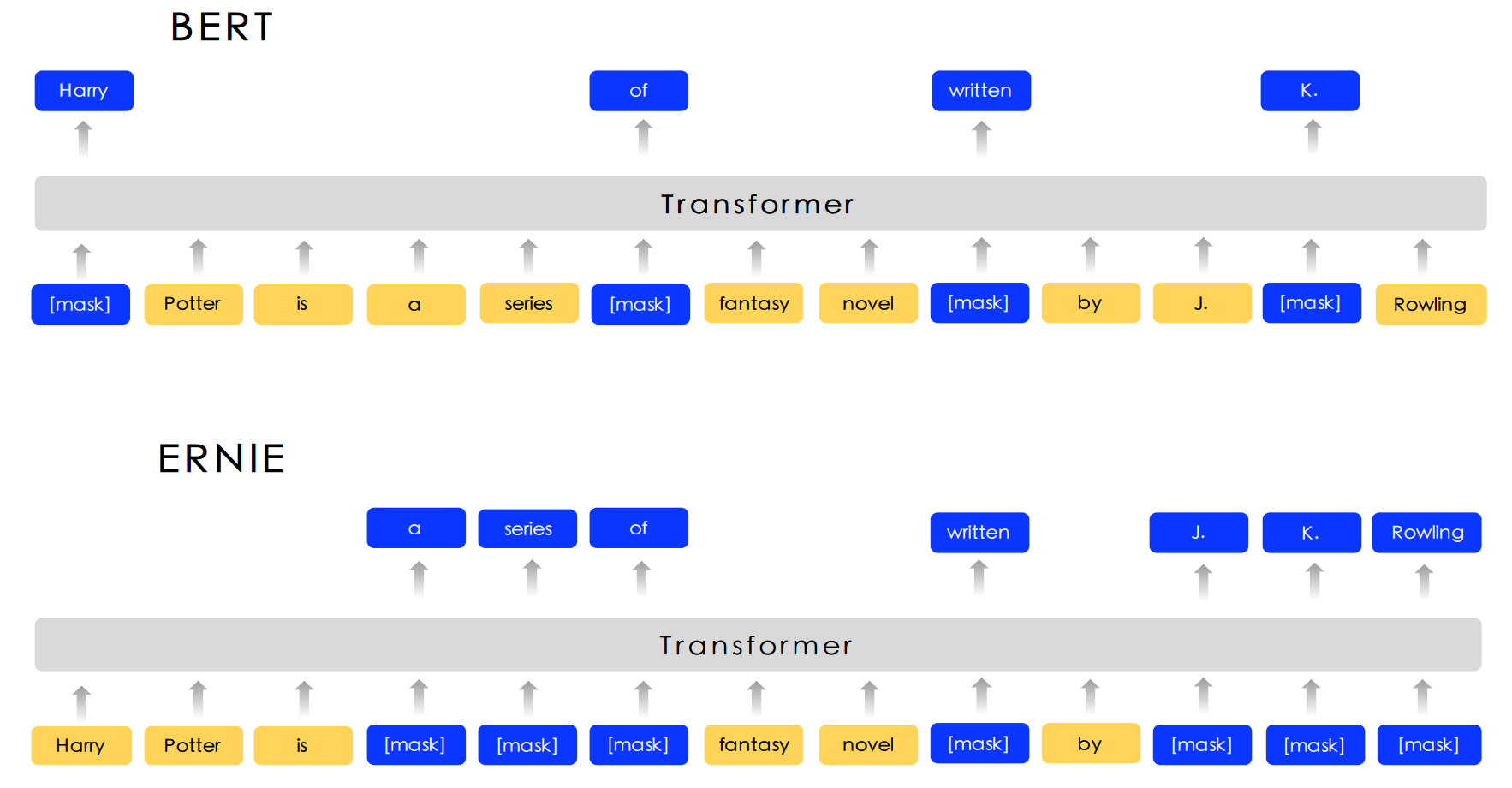
ERNIE models the Query-Response dialogue structure on the DLM (Dialogue Language Model) task. The model is designed to judge whether the multi-turn conversation is real or fake. we generate fake samples by replacing the query or the response with a randomly selected sentence. The model architecture of DLM task is compatible with that of the MLM task.

ERNIE 2.0 is a continual pre-training framework which incrementally builds pre-training tasks and then learn pre-trained models on these constructed tasks via continual multi-task learning by capturing a wide range of valuable lexical, syntactic and semantic information in the training data.
The framework of ERNIE 2.0 is:

The process of continual pre-training contains two steps.
- Firstly, we continually construct unsupervised pre-training tasks with big data and prior knowledge involved. There are different kinds of pre-training tasks including word-aware, structure-aware and semantic-aware tasks. 7 pre-training tasks belonging to different kinds are constructed in the ERNIE 2.0 model.
The model architecture of ERNIE 2.0 is:

As we see, the input embedding of ERNIE 2.0 contains the token embedding, the sentence embedding,the position embedding and the task embedding.
- Secondly, we incrementally update the ERNIE model via continual multi-task learning without forgetting the knowledge learned before. Whenever a new task comes, the continual multi-task learning method first uses the previously learned parameters to initialize the model, and then train the newly-introduced task together with the original tasks simultaneously by automatically allocating each task N training iterations to the different stages of training.
9.Reference
official implementation of Transformer based on tensor2tensor