named entity recognition methods
Named entity recognition is known for extracting specific information such as person, location, organization, time and other predefined category from text.
HMM
HMM (Hidden Markov Model) is a generative model that compute joint probability of states and observations. Besides, it is based on the directed graph. HMM has three important elements: initial state probability; state transition probability matrix; emission probability matrix. There are two fundamental precondition for HMM: observation sequence is mutually independent, this is to say, the current observation only rely on the current state; Secondly, the current state only depends on last state.
The existence of these two constraints result in some severe problems: the recognition of named entity doesn’t take the long-distance context and more feature into consideration.
CRF
CRF (Conditional Random Field) is a discriminative model that compute conditional probability of states conditioned on the observations and is based on undirected graph. CRF exploits the context of states and observation to predict the appropriate result. But a lot of feature functions is designed by human.
BI-LSTM
BI-LSTM (Bidirectional Long Short Term Memory) is a specific version of RNN (Recurrent Neural Network) that aims to solve the tasks about temporal relation such as text and speech. It can extract feature of input text automatically and deeply without any human intervention.

Furthermore, one attention layer can be added to the top of LSTM to make good use of the contextual information.
BI-LSTM-CRF
One disadvantage of BI-LSTM is: there exists strong and natural correlation between network outputs (BIEO label). But pure BI-LSTM doesn’t take that into account, sometimes it generates the unreasonable output label. For example, B-Person is followed by I-Location, which is obviously wrong.
CRF layer is put on top of BI-LSTM to lay constraints between output labels by a label transition probability.
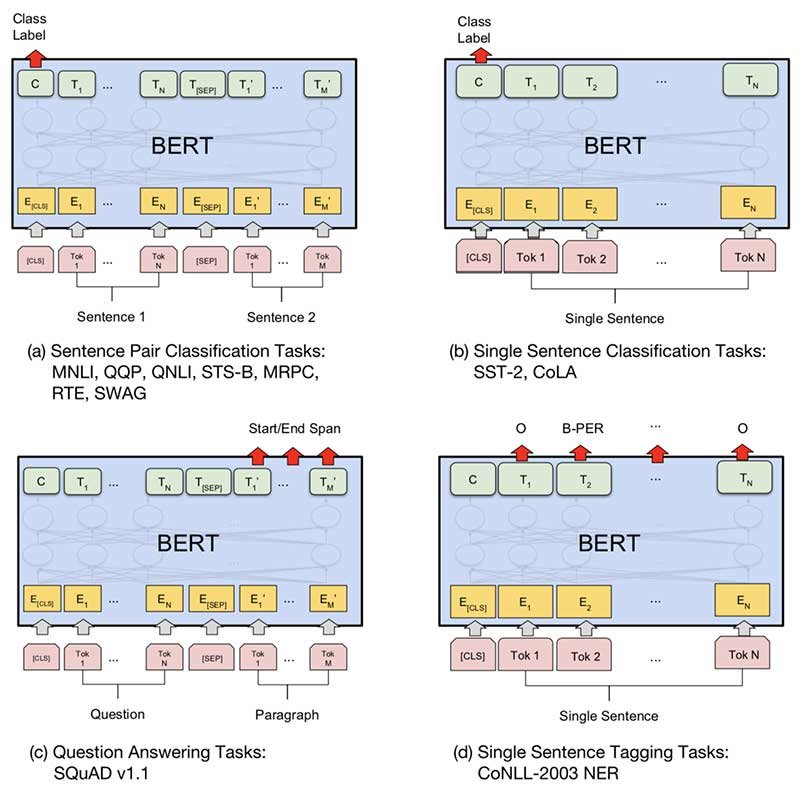
BERT-BI-LSTM-CRF
Compared to the BI-LSTM, BERT (Bidirectional Encoder Representations from Transformers) model has stronger ability of feature extraction and representation. BERT is composed of transformers encoder block and use multi self-attention layer to replace traditional RNN structure to mine the contextual relation. In additional, it applies large unlabelled data set to pre-train the neural network on the tasks: Masked Language Model (MLM) and Next Sentence Prediction (NSP)
BERT pretraining:

BERT fine-tuning: